阿里开源端到端语音交互模型 Fun-Audio-Chat,实现高效语音交互的新里程碑
阿里开源了一个端到端的语音交互模型,名为Fun-Audio-Chat,该模型旨在提供高效、可靠的语音交互体验,支持实时语音通信和语音识别功能,通过端到端的处理方式,该模型能够更好地处理语音信号,提高语音交互的准确性和流畅性,该模型的开源性质将有助于促进语音交互技术的发展和创新,推动人工智能领域不断进步。
通义大模型微信公众号正式发布全新一代端到端语音交互模型——fun-audio-chat。“不止于‘会说话’,更懂你言外之意、识你情绪起伏、助你高效办事——这才是真正懂你的ai语音伙伴。”

当前已开源 Fun-Audio-Chat 8B 版本,完整提供模型权重、推理代码及 Function Call 集成示例。
核心技术亮点:
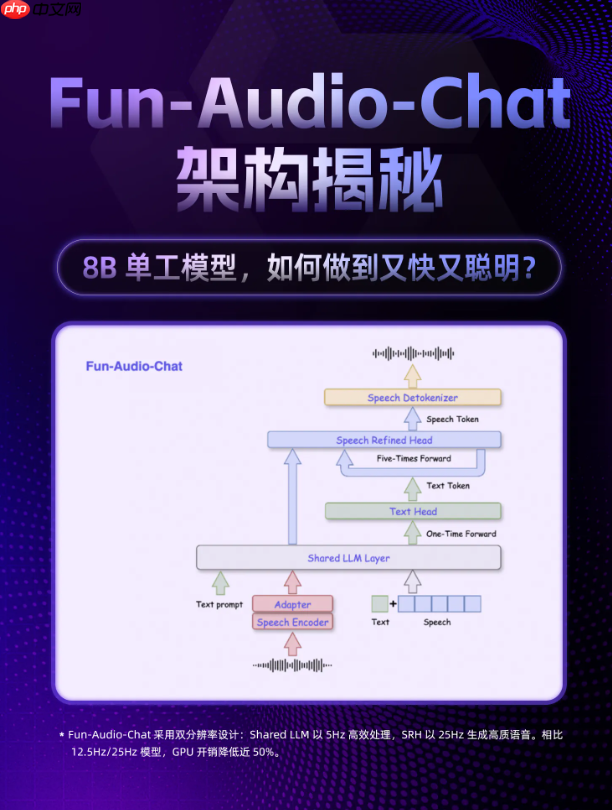
- 全链路端到端 S2S 架构:语音输入直出语音响应,跳过传统 ASR + LLM + TTS 多模块串联流程,显著提升响应速度、降低系统延迟。
- 创新双分辨率协同机制:Shared LLM 主干以 5Hz 帧率高效建模语义,SRH 模块以 25Hz 帧率精细合成语音,整体 GPU 资源消耗下降近 50%。
- 百万小时多任务真实数据训练:涵盖语音理解、口语问答、情绪判别、工具调用等丰富场景,让模型更贴近用户日常表达与真实需求。
高共情:如知己般自然流畅的对话体验
- 当你低落,它主动给予温暖回应;当你紧张,它引导你一起做呼吸练习;当你雀跃,它也能即刻加入你的节奏,共享喜悦。
- 即便你未曾明说心情,它也能敏锐捕捉语气轻重、语速快慢、停顿长短等细微线索,精准识别情绪状态,并作出体贴入微的反馈。
强实用:不止能聊,更能“上手就干”
- 支持 Speech Function Call:用户仅需自然口语发出指令,模型即可自主解析意图、触发对应函数,无缝执行查天气、设提醒、订机票等复杂操作。
实测表明,Fun-Audio-Chat 8B 在 OpenAudioBench、MMAU、Speech-ACEBench、VStyle 等多项主流语音多模态评测中,均在同参数量级模型中位列榜首,综合能力全面领先 GLM4-Voice、Kimi-Audio、Baichuan-Omni。
源码获取地址:点击下载
<< 上一篇
下一篇 >>
网友留言(0 条)