vLLM-Omni上线,简化多模态推理,速度提升,成本降低
vLLM-Omni已上线,实现了多模态推理的简化、提速和节能,该系统通过集成先进的算法和技术,使得跨模态数据处理更为便捷高效,用户无需复杂的操作,即可享受快速且省力的多模态推理服务,vLLM-Omni的推出将极大提升各类应用场景下的用户体验,推动多模态推理技术的普及和发展。
vllm 团队正式推出vllm-omni:这是 vllm 生态迈向“全模态(omni-modality)”时代的重要里程碑,专为新一代具备视觉感知、语音理解、多轮对话与多媒介生成能力的模型打造的高性能推理框架。


自诞生以来,vLLM 始终聚焦于为大语言模型(LLM)提供高吞吐、低显存占用的推理解决方案。然而,当前的生成式 AI 模型早已突破“文本到文本”的单一范式:现代模型能够同时处理和生成文本、图像、音频乃至视频内容,其底层架构也从单一的自回归模型,演变为融合编码器、语言模型、扩散模型等异构模块的复杂系统。
vLLM-Omni 是首批支持“全模态”模型推理的开源框架之一,它将 vLLM 在文本推理方面的卓越性能,成功拓展至多模态与非自回归推理场景。

vLLM-Omni 并非在原有 vLLM 架构之上简单叠加功能层,而是从数据流(data flow)的本质出发,对整个推理流程进行了重构。它引入了一套完全解耦的流水线架构,使得各个处理阶段可以独立分配资源,并通过统一调度机制高效协同。
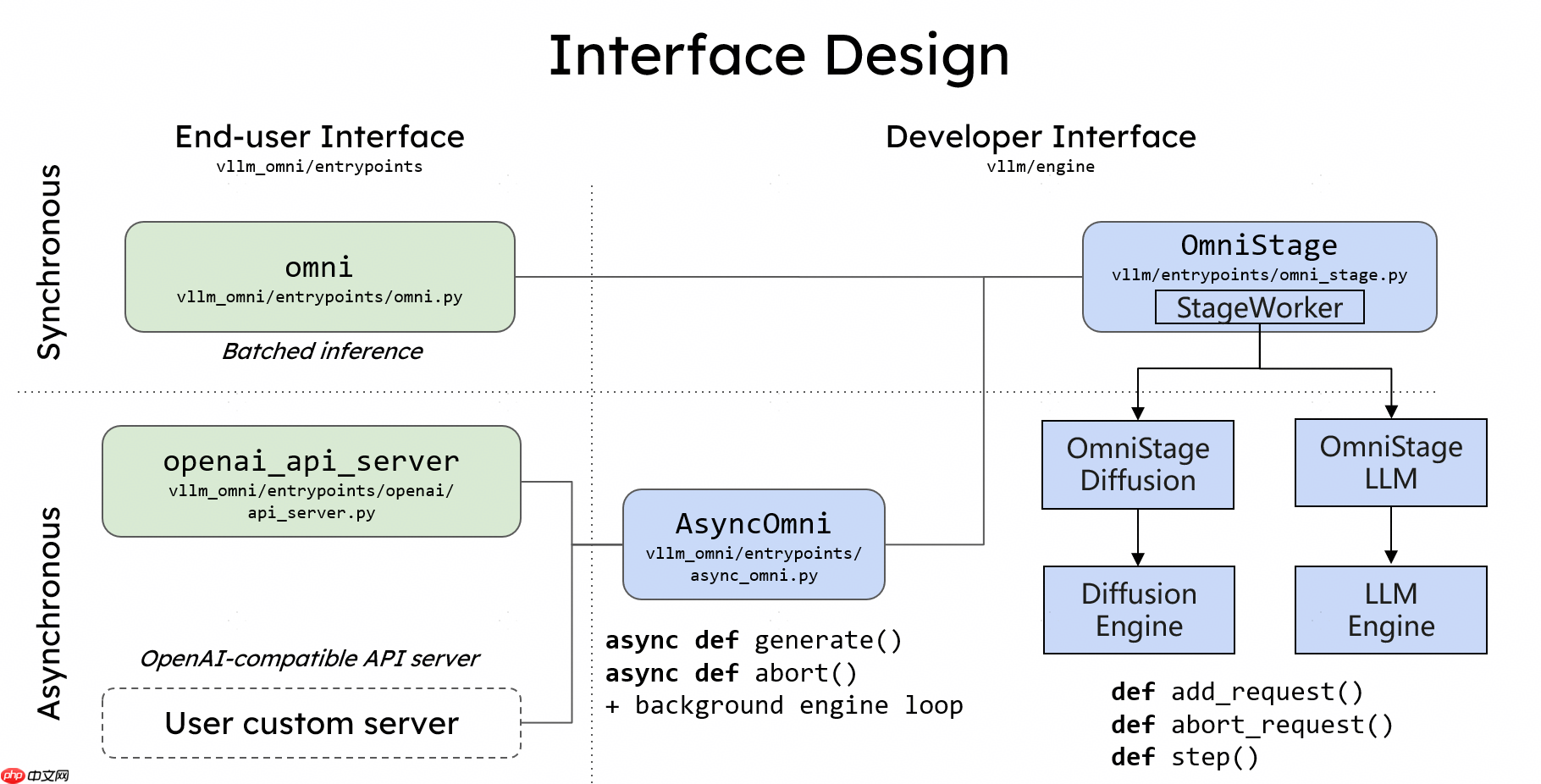
在此架构下,一个全模态推理请求通常会经过以下三类核心组件:
- 模态编码器(Modality Encoders):负责将来自不同模态的输入(如图像、语音)高效编码为向量或中间表示,例如 ViT 视觉编码器、Whisper 语音编码器等。
- LLM 核心(LLM Core):基于 vLLM 的自回归引擎,承担文本生成、语义理解和多轮对话逻辑,可集成一个或多个语言模型。
- 模态生成器(Modality Generators):用于生成非文本内容的解码头,如基于 DiT 的图像扩散模型、音频合成模型等。
这些组件并非简单的串行连接,而是在 vLLM-Omni 的调度中枢协调下,跨 GPU 或跨节点并行协作。对于实际部署的工程团队而言,这意味着:
- 各阶段可独立进行扩缩容与拓扑优化;
- 能根据实际负载瓶颈(如图像生成延迟或文本推理压力)动态调整资源配置;
- 支持在不改动整体结构的前提下灵活替换任一组件(例如升级至更先进的视觉编码器)。
代码与文档:
GitHub 仓库:https://www.php.cn/link/e12612acc5951b13ed502266385b8108
文档站点:https://www.php.cn/link/1f59187dda99471222b710b5b3a39a3e
源码地址:点击下载
<< 上一篇
下一篇 >>
网友留言(0 条)