阿里云发布全球首个全模态AI模型Qwen3-Omni
阿里云推出全球首个全模态AI模型Qwen3-Omni,该模型具备跨模态感知与生成能力,可广泛应用于自然语言处理、计算机视觉等领域,这一创新技术的推出将有助于推动人工智能技术的进一步发展和应用,提升全球范围内的智能化水平,Qwen3-Omni模型具备强大的多模态交互能力,能够理解和生成不同形式的信息表达,为人工智能的发展注入了新的活力。
阿里云正式推出 qwen3-omni,宣告全球首个原生端到端全模态 ai 模型诞生,该模型现已全面开源。qwen3-omni 能够处理文本、图像、音频和视频等多样化输入形式,并支持实时流式输出,无论是通过文字还是自然语音交互,均可实现快速响应。

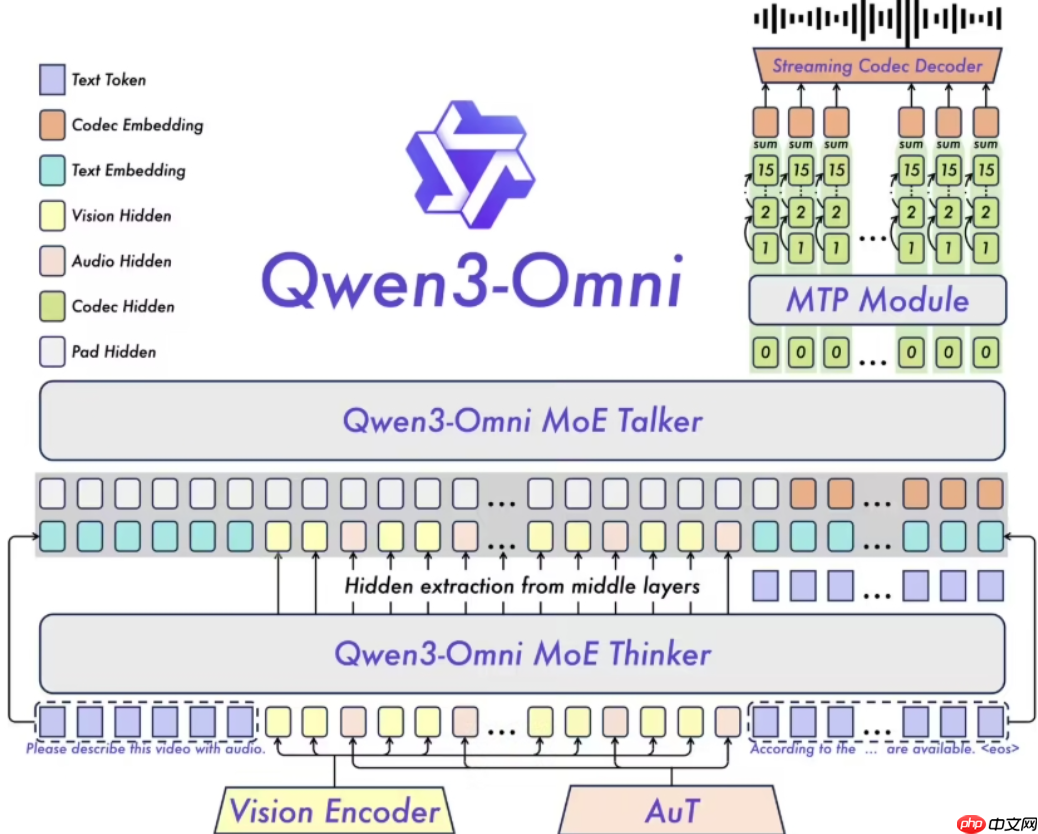
在多个应用场景中,Qwen3-Omni 展现出卓越的跨模态能力。其核心技术依托于早期以文本为中心的预训练策略与混合多模态训练方法,从而构建出强大的多模态理解力。尤其在音频与视频任务中表现突出,同时在文本和图像处理方面也维持了高水准。根据涵盖36项音频与视频基准测试的结果显示,Qwen3-Omni 在其中22项中达到了当前最优水平,其在自动语音识别与音频理解方面的性能已可媲美行业领先的 Gemini2.5Pro。
该模型支持多达119种文本语言,兼容19种语音输入语言以及10种语音输出语言,涵盖英语、中文、法语、德语等主流语种,具备广泛的国际化服务能力。其架构创新性地采用 MoE(专家混合)系统,并融合 AuT 预训练机制,赋予模型强大的通用表征能力。此外,多码本设计保障了音频与视频交互的低延迟特性,确保自然对话过程流畅无卡顿。
除 Qwen3-Omni 外,阿里云还发布了 Qwen3-TTS,一款支持17种音色选择的文本转语音模型。该模型在多项权威评测中超越同类产品,尤其在语音稳定性与音色还原度方面表现亮眼。
同期推出的还有 Qwen-Image-Edit-2509,专注于提升图像编辑能力,支持多图协同编辑,显著增强编辑结果的一致性与视觉效果。它不仅适用于单张图像修改,还能实现多图拼接与联动调整,满足复杂图像处理需求。
源码地址:点击下载
网友留言(0 条)