微软发布开源数学推理模型rStar2-Agent,引领智能推理新纪元
微软发布开源数学推理模型rStar2-Agent,该模型具备强大的数学理解和推理能力,可广泛应用于自然语言处理领域中的数学问题解答和数学推理任务,该模型的开源发布旨在促进学术界和工业界在数学智能方面的合作与进步,推动数学推理和自然语言处理技术的进一步发展,通过使用rStar2-Agent模型,用户能够更轻松地解决复杂的数学问题,并享受更智能的数学推理体验。
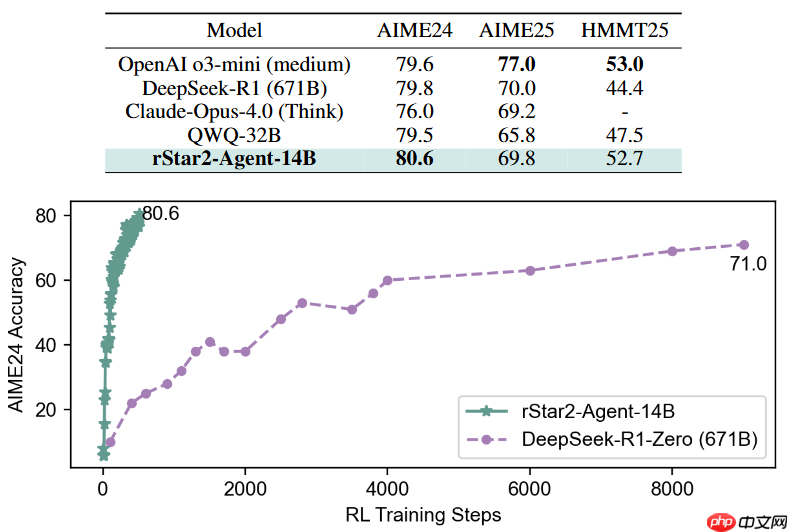
微软近日推出了一款名为“rstar2-agent”的开源模型,这是一个拥有140亿参数的数学推理模型,凭借更智能而非冗长的思维过程,实现了与6710亿参数的deepseek-r1模型相媲美的性能表现。

该模型具备自主规划、逻辑推理以及调用代码工具的能力,能够高效地探索、验证并反思复杂问题的解决方案。其卓越能力源于三大关键技术突破:GRPO-RoC算法、可扩展且高效的强化学习(RL)基础设施,以及从非推理SFT起步的渐进式Agent训练策略。
rStar2-Agent的核心理念是“更聪明地思考”,而非延长推理链长度。通过纯智能体式的强化学习训练,其在多项任务上的表现已接近甚至超越超大规模模型,如671B参数的DeepSeek-R1。
该模型能够自主进行任务规划、逻辑推导,并灵活运用编程工具,从而高效完成对复杂问题的求解、验证与自我修正。
- GRPO-RoC算法:引入创新的“正确时重采样”推理机制,优化了对编码工具的使用效率。该方法选择性保留高质量的成功推理路径,同时完整保留失败案例用于学习,从而实现更短但更高效的推理过程;
- 高效可扩展的RL基础设施:支持高吞吐量的工具调用执行,显著降低智能体在强化学习推演中的资源消耗,使得仅用64块MI300X GPU即可完成大规模训练;
- 渐进式Agent训练方案:起始于非推理型SFT模型,通过多阶段强化学习逐步提升能力。每一阶段均采用受限的最大响应长度,并逐步提高训练数据的难度,确保稳定收敛。
基于上述技术,rStar2-Agent仅用一周时间、经过510步的强化学习训练,就将一个14B参数的预训练模型提升至行业领先水平。在AIME24和AIME25两个权威数学评测集上,分别取得了80.6%和69.8%的平均通过率,响应更简洁却超越了参数量高达6710亿的DeepSeek-R1。
此外,rStar2-Agent-14B在数学之外的任务中也展现出出色的泛化能力,包括指令对齐、科学推理以及智能体工具调用等多样化场景。
开源地址:https://www.php.cn/link/b1946b34ce976b3f223d5afc2052e89d
<< 上一篇
下一篇 >>
网友留言(0 条)