腾讯开源发布混元翻译模型Hunyuan-MT
腾讯发布开源混元翻译模型Hunyuan-MT,该模型具备高效、准确的机器翻译能力,通过深度学习技术,它能够自动学习不同语言的语法和语义规则,实现高质量的语言翻译,该模型的开源将促进机器翻译技术的发展和应用,有助于打破语言壁垒,推动全球化进程。
腾讯混元团队近日宣布开源专为翻译场景设计的 hunyuan-mt 系列模型,正式对外开放。目前该系列包含两个主要版本:

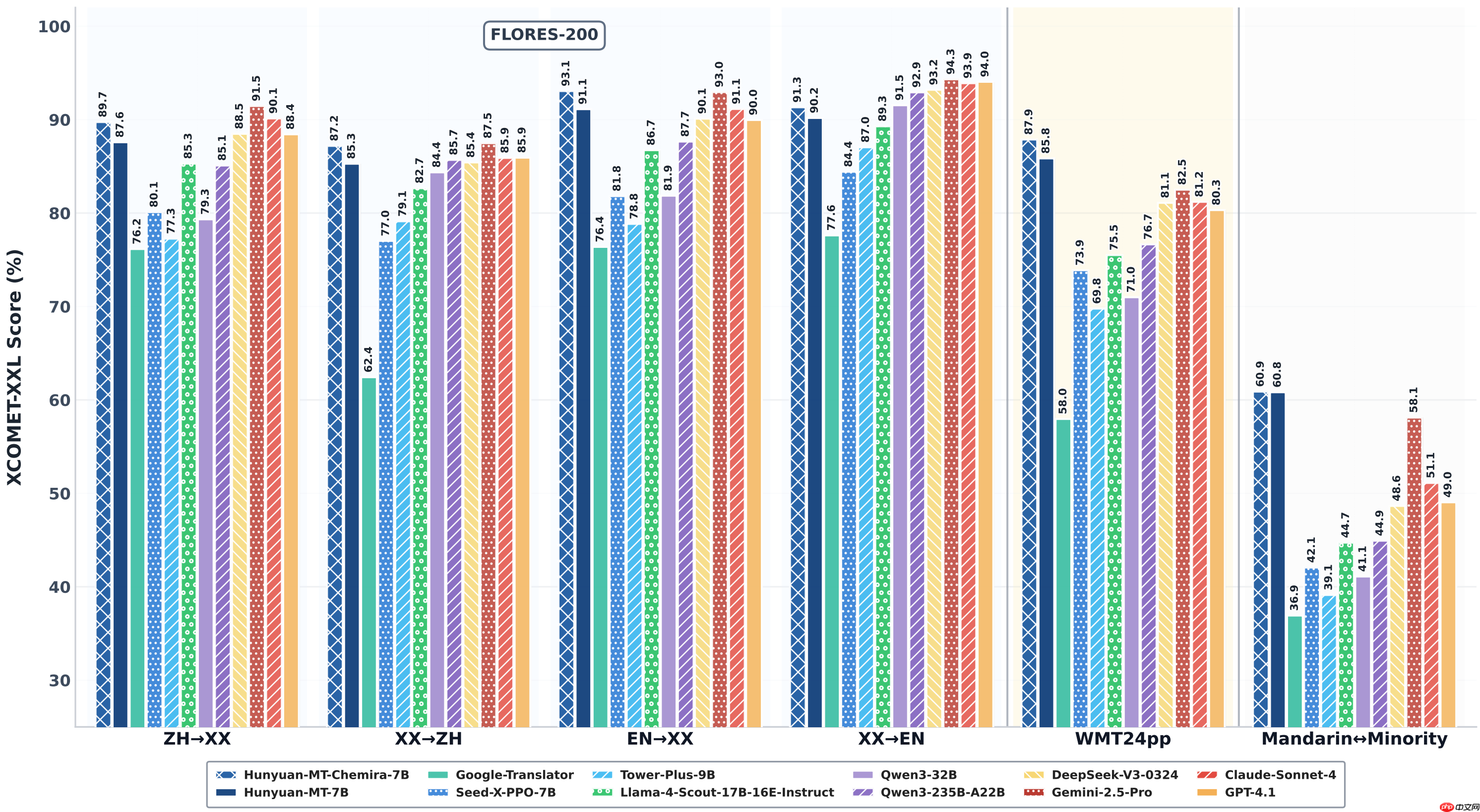
- Hunyuan-MT-7B:单体模型,支持中、英、日、法等主流语言在内的 33 种语言双向互译,同时涵盖藏语、维吾尔语、蒙古语、哈萨克语、朝鲜语等 5 种中国少数民族语言;在 WMT25 竞赛涉及的 31 个语言方向中,取得了 30 项第一的优异成绩。
- Hunyuan-MT-Chimera-7B:集成式模型,通过融合多个翻译路径的输出结果,显著提升翻译准确性和流畅度。
在相同参数规模下,Hunyuan-MT-7B 实现了当前业界领先的翻译能力,而 Hunyuan-MT-Chimera-7B 作为首个开源的翻译集成模型,进一步将翻译质量推向新高度。
核心亮点与优势
- 在 WMT25 参与评测的 31 个语种方向中,斩获 30 个第一名。
- Hunyuan-MT-7B 在同尺寸模型中翻译效果达到最优水平。
- Hunyuan-MT-Chimera-7B 为全球首个开源的翻译集成模型,显著增强输出质量。
- 构建了一套完整的翻译模型训练流程:Pretrain → CPT → SFT → 翻译强化 → 集成强化,最终实现同规模模型中的 SOTA 表现。
性能表现
开源地址:https://www.php.cn/link/414c073ee1379bd7bc7b332159cab1e6
网友留言(0 条)